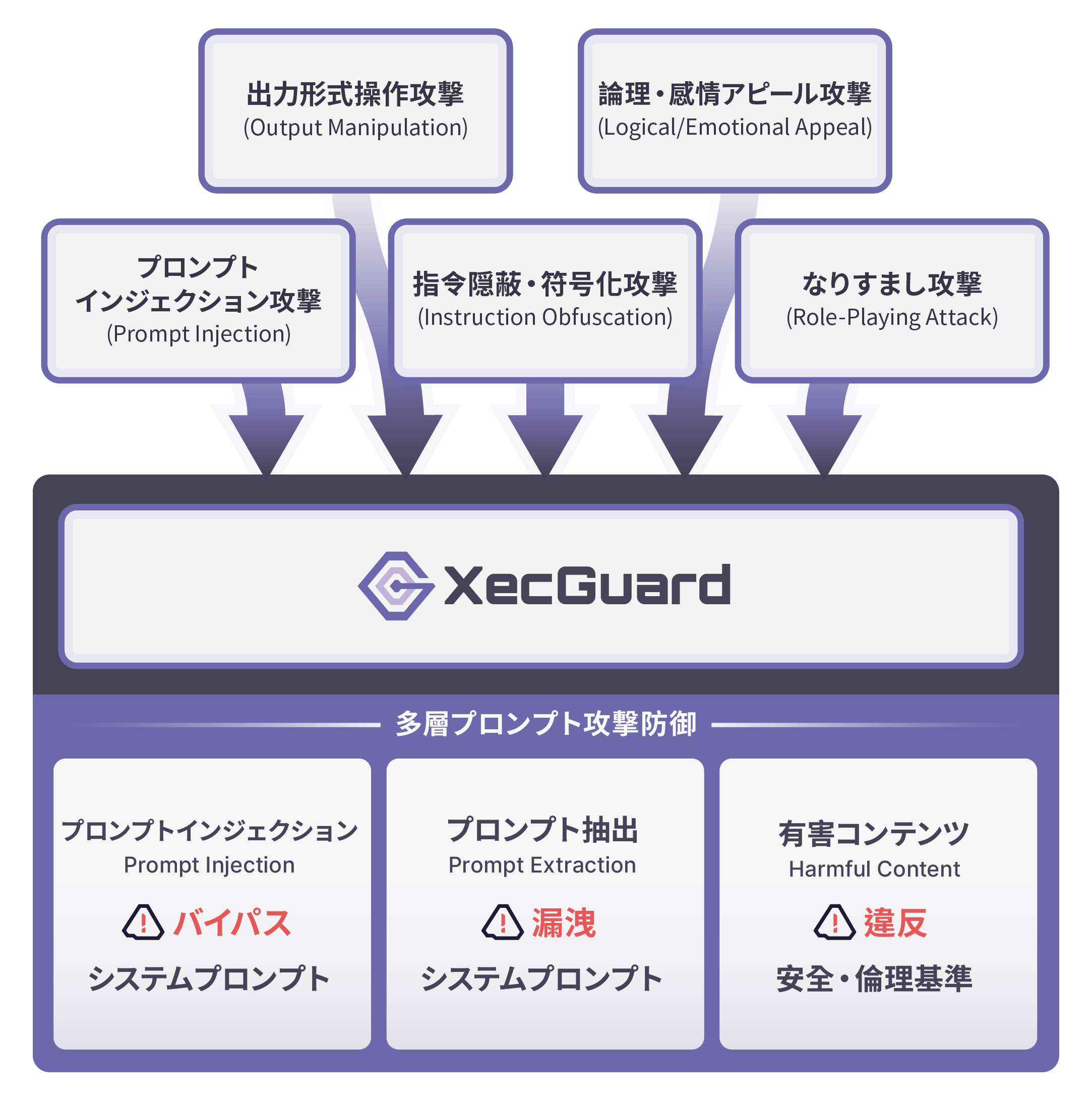
XecGuard: AI Chatbot / LLM のために構築されたセキュリティガードレール
XecGuard は、CyCraft が開発した AI セキュリティ防護用の Guardrail API であり、大規模言語モデル(LLM)を標的とした各種 Prompt Attacks を防御するために設計されています。悪意のある対話内容をリアルタイムで検知・分析し、包括的な LLM Safety 防護機能を提供します。XecGuard は特に AI Agent や各種 AI アプリケーションの利用シーンに適しており、Prompt Injection、Prompt Extraction、Harmful Content、攻撃的なプロンプトなど、外部からの悪意ある入力を効果的に防止できます。これにより、モデルが誤った内容を生成したり、タスク範囲から逸脱したり、さらには有害な行動を取るよう誘導されることを防ぎ、システム全体の安全性と信頼性をさらに向上させます。
コア保護メカニズムと特徴
XecGuard は、セキュリティシナリオ専用に設計された軽量なセマンティックモデルを採用しています。キーワードフィルタリングに依存する従来の保護メカニズムとは異なり、「攻撃意図」や「セマンティックな変化」を理解することができます。主な強みは以下のとおりです:
- マルチモデルファインチューニング技術:キーワードフィルタリングに頼るのではなく、XecGuard は複数の小型モデルの協調によって駆動されます。これらの小型モデルは、特定のセキュリティタスクに高度に特化するようファインチューニングされています。
- 高性能・低遅延:単一の大型モデルではなく小型モデルアーキテクチャを採用することで、計算コストを抑えつつ高速な処理速度を実現します。
- 高精度:各モデルは特定のセキュリティタスク向けにファインチューニングされており、セマンティック認識と投票方式により、高精度な検知を保証します。
- 多層的な脅威防御:Prompt Injection、Prompt Extraction、Harmful Content を効果的にブロックします。
- 悪意あるセマンティック認識:深層的な「攻撃意図」や「セマンティックな変化」を理解でき、User Prompt 内の悪意あるセマンティクスを認識する能力を備えています。攻撃者が Instruction Obfuscation、Role-Playing、感情訴求などの手法を用いても、システムは背後にある悪意あるロジックを正確に見抜くことができます。
- コンテキスト指示遵守:AI が System Prompt で定義されたタスク範囲を厳格に守り、ユーザーによって許可されていないタスクコンテキストへ誘導されることを防ぎます。
- 多言語およびローカライズの優位性:中国語、英語、日本語を含む多言語分析をサポートします。中国語や日本語におけるセマンティック攻撃を正確に識別するだけでなく、台湾ローカルの PII フォーマット(身分証番号、住所、金融口座番号など)の検知も強化されており、クロスボーダーおよびローカル双方のコンプライアンス要件を満たします。
8 つのコア機能モジュール
XecGuard は包括的な AI 保護機能を提供しており、以下の主要モジュールを含みます:
- General Prompt Attack Protection:モデルの挙動を上書きしたり、保護された指示を露呈させたり、セキュリティ機構をバイパスしようとする Prompt Injection、Extraction、回避(Evasion)行為を検知・防止します。難読化を用いた攻撃も対象です。
- System Prompt Enforcement:エンタープライズ AI 向けのコンテキスト認識型タスク遵守機構により、AI システムが企業から与えられたタスク範囲内に厳格にとどまるよう維持し、従来のコンテンツフィルタリングを超えた真のコンテキスト認識型セキュリティを実現します。
- Content Bias Protection:偏見、嫌がらせ、有害なステレオタイプを示す出力を検知・緩和し、生成されたコンテンツが差別的でないこと、また保護対象属性、健康状態、社会経済的指標を尊重することを保証します。
- Harmful Content Protection:単純なキーワードフィルタリングを超えてセマンティックな意図を分析することで、有害または危険な AI 出力を検知・防止します。
- PII & Sensitive Data Protection:エンタープライズ AI 向けのプライバシーおよびデータ漏洩防止機能を提供し、個人情報や機微情報が AI によって露出しないようにします。
- Malicious Skills Protection:AI Agent の Skills および関連ファイル内容に、システムに対する悪意ある、または有害な内容が含まれていないかを検知し、Agent AI を悪意ある Skills の影響から保護します。
- Custom Policy Enforcement:組織が自社の業務や AI / Chatbot のタスク要件に応じて、自然言語でカスタム Guardrail Rules を定義し、組織固有の AI ガバナンスルールとして強制適用できるようにします。
- Context Grounding Validation:応答内容がユーザー提供のドキュメントおよび承認済み RAG コンテキストに厳格に基づいていることを保証することで、AI のハルシネーションを検知します。
API 統合とシステム導入
- 標準的でシンプルな API 統合:標準的な RESTful API アーキテクチャを採用しています。呼び出し規約は市場の主要 LLM サービス(OpenAI など)と互換性があり、開発者は HTTP Header に専用の Management Token / Service Token(API Key)を含めるだけで、認証および統合を迅速に完了できます。詳細については、ユーザーガイド をご参照ください。
- 多様なライセンスプラン:Lite、Standard、Advanced の 3 ティアにわたる柔軟なプランを提供します。POC 検証から大規模エンタープライズ導入まで幅広いニーズをカバーし、企業はアプリケーション規模に応じて最適なセキュリティ保護を柔軟に割り当てることができます。Standard 以上のプランでは専用 GPU サーバーを利用し、隔離された計算リソースと持続的なハイパフォーマンスを保証します。
- すべての正常なリクエスト内容は記録・保存されません。悪意ある攻撃(Prompt Attacks など)が検知された場合にのみ、関連内容が非識別化されたうえで一時保存されます。これは、セキュリティ研究、モデル最適化、および AI セーフティの推進を目的としています。また、当社は研究成果を継続的にオープンソースコミュニティへ還元し、エコシステム全体のセキュリティ能力向上を促進していきます。このような好循環を通じて、オープンソースコミュニティとともに、より安全で信頼できる AI 開発環境を構築していくことを目指しています。
XecGuard は、企業向け AI アプリケーションにおける「セキュリティファイアウォール」として、AI システムが安全・コンプライアンス遵守・制御可能な環境で運用されることを確保します。企業が生成 AI を導入するプロセスにおいて、不可欠なセキュリティ基盤です。